前言
大家都知道,windows的可执行成功被称作pe文件,那么今天这篇文章主要是回顾一些更加基础的内容,windows的pe文件的结构,同时还介绍下如何在内存中找到各个模块基地址的方法。
PE文件的结构
先来看下这张图,这是很久前作的比较,鉴于当时的理解,就按照这种方式来展开今天的介绍,一个pe文件,无论在硬盘了的文件,还是在加载到内存里,都大概会存在这样几个部分。
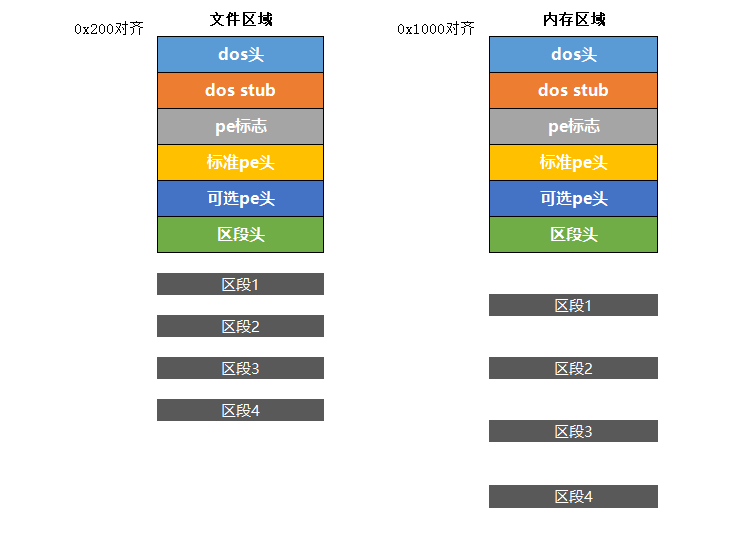
首先是,头区域,包含几个header,每一个header都有其作用,然后是区段,每个区段存储着不同的数据,有的是代码,有的是常量,比如一些字符串,还有的可能是函数的地址,等等。正因为存储的内容不同,每个区段大小不一,那么就需要一个头来描述每个区段的情况,那就是区段头。
其次,每个区段虽然大小不一样,但是考虑到存储的规格效果,每个区段的大小至少要是某个单元大小的整数倍,比如,0x200,区段可能存储的数据就是0x996,那为了方便分配大小,在文件里就给你对齐到0x1000,方便你存储。
最后,因为在硬盘里存储的时候,文件是紧凑的方式,而在当文件加载到内存的时候,涉及到逻辑地址和物理地址的映射以及页的交换等,一般会进行更大单位的对齐,比如,文件是0x200的整数倍,那么到了内存,这个区段的大小可能就变成了0x1000的整数倍,很有可能会导致,对齐后区段尾巴的空余空间增加了。
PE文件的图示结构
下面放三张网传很多的pe文件的格式示意图(如果图片看的不清晰可以右键另存为下载看):

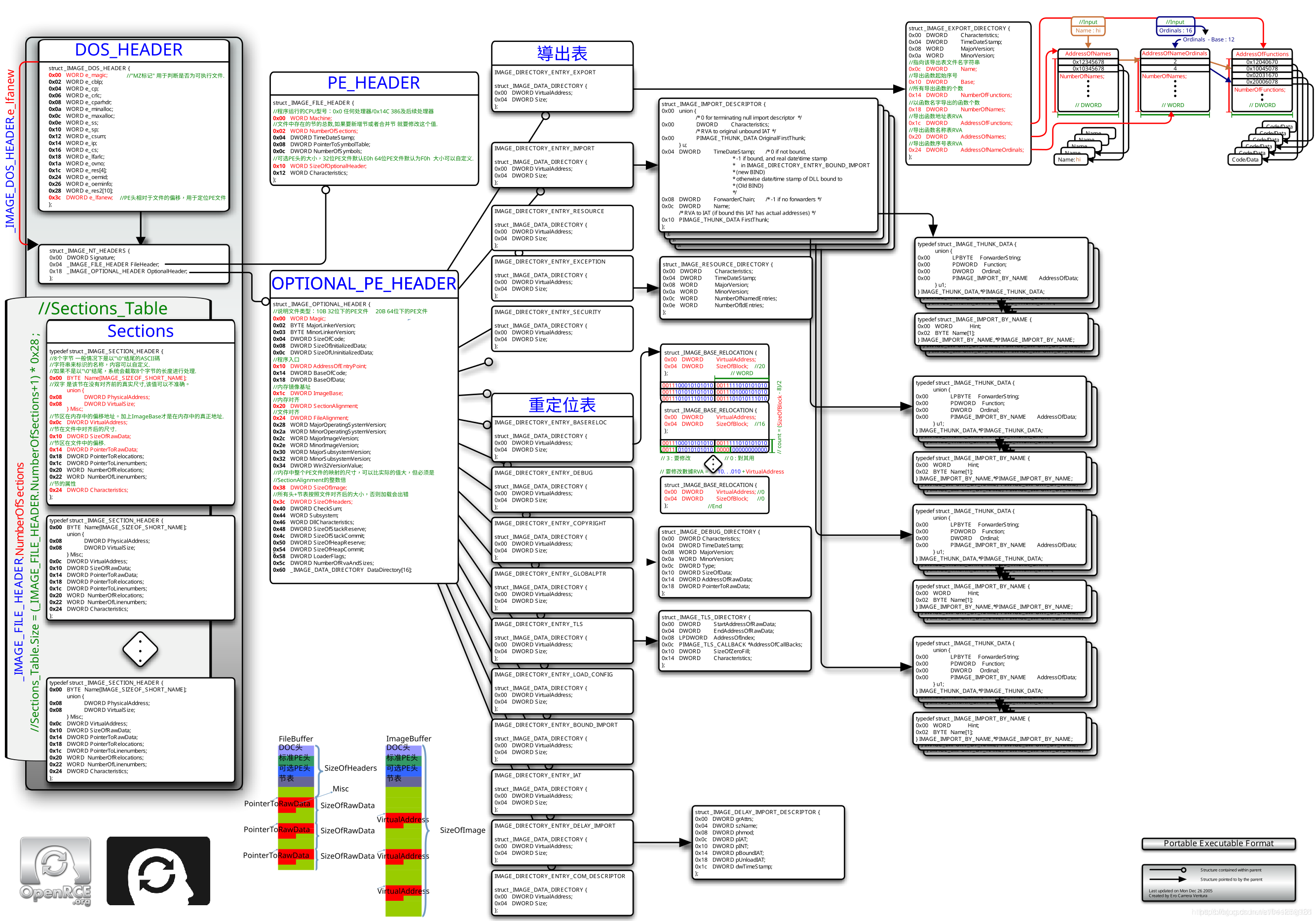
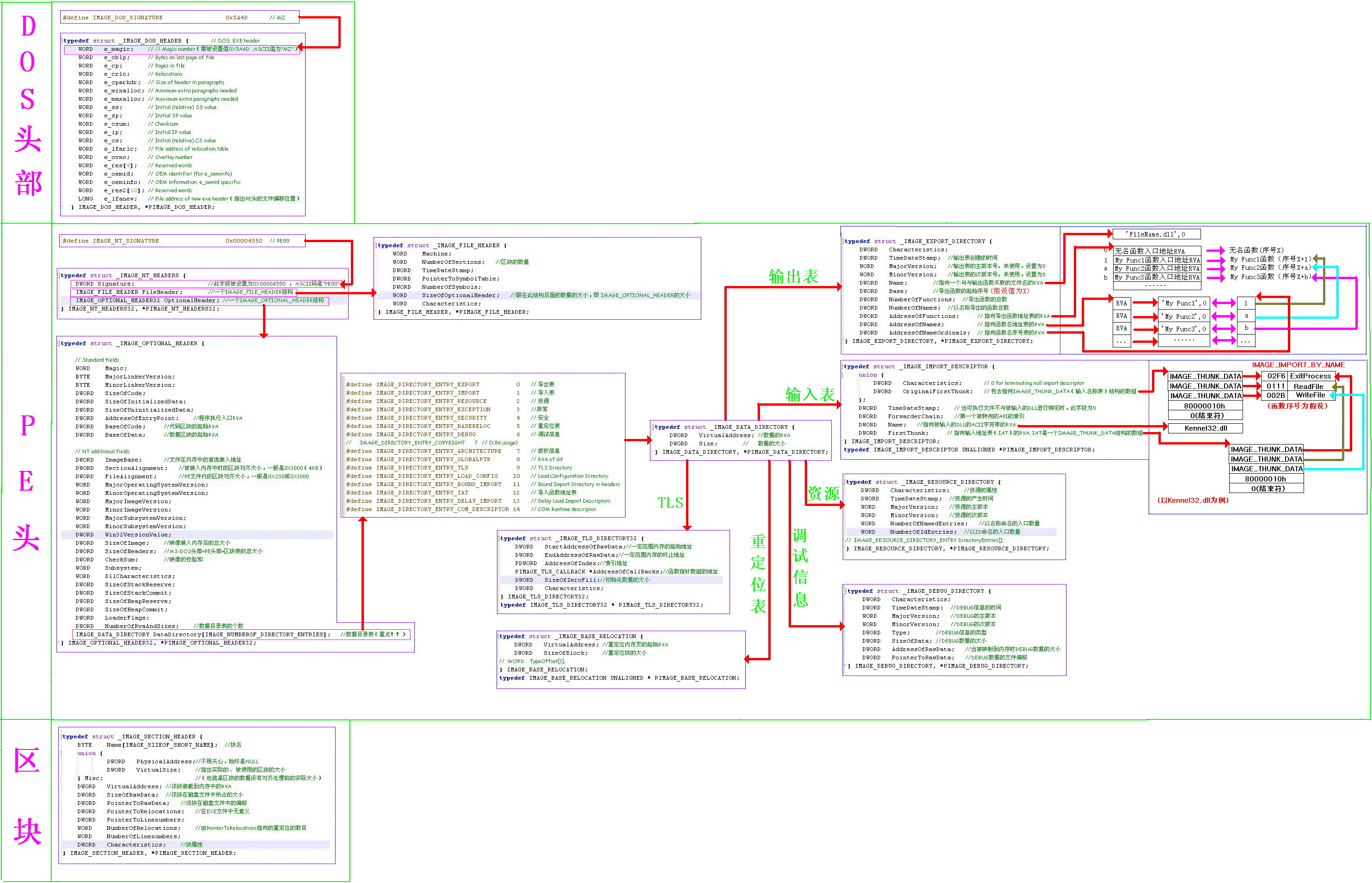
各个结构的情况
首个pe结构就是dos头,我们可以用一个叫做010editor的工具来查看任意一个pe文件,具体哪里获取,还是跟之前说的方法一样哈,具体不多说。
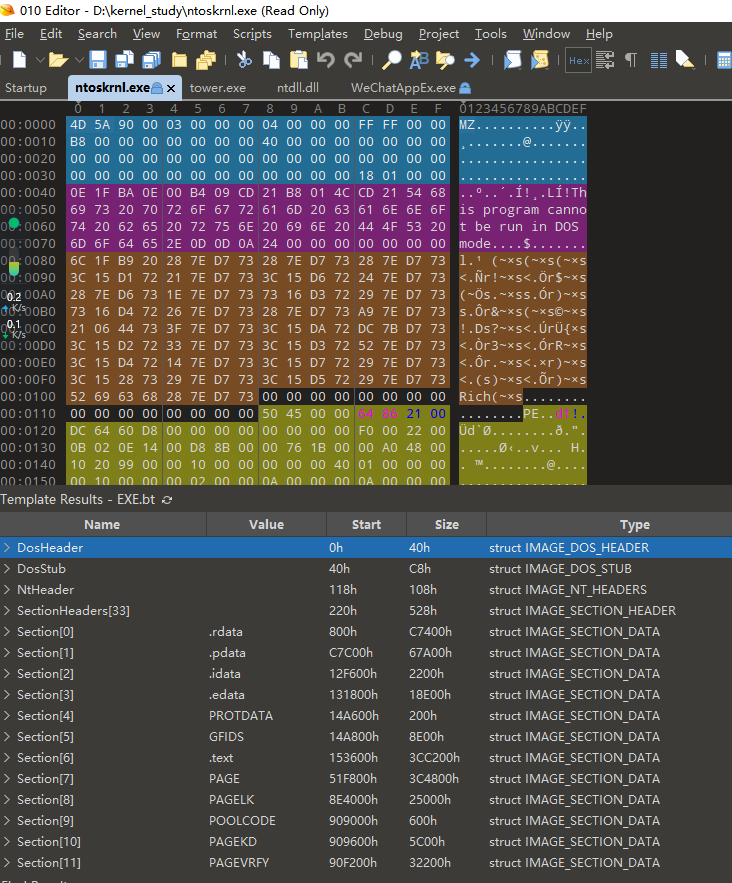
我们打开一个之前在驱动的时候说过的文件,内核文件(ntoskrnl.exe),这个软件已经清晰的帮我们把所有的结构都区分清楚了,而且还右面的类型上有指出对应的结构体类型
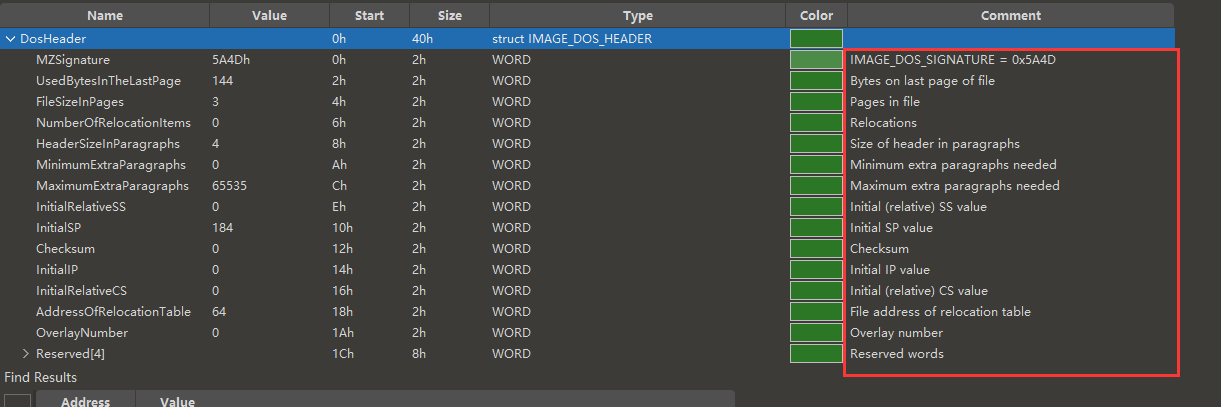
进一步展开会发现,结构体每一个单元的名称,值,起始地址和大小,值的类型都罗列清除,同时在评论区还会介绍这个值的一些含义,接下来我们展开介绍下每一个区段。
DosHeader
这部分是整个pe文件的最起始位置,
|
|
其中,WORD e_magic; 就是典型pe文件的标志,0x5A4D;然后LONG e_lfanew; 是文件头的偏移地址,结合官方的部分介绍,这个dos头是在早期传统的dos文件的主要头文件,但是因为后期产生了新的pe格式的文件,所以真正的pe文件头是在下一个段开始,所以e_lfanew真正pe文件头开始位置的偏移。(我可能说的也不对,不过不重要,知道值的含义就行)
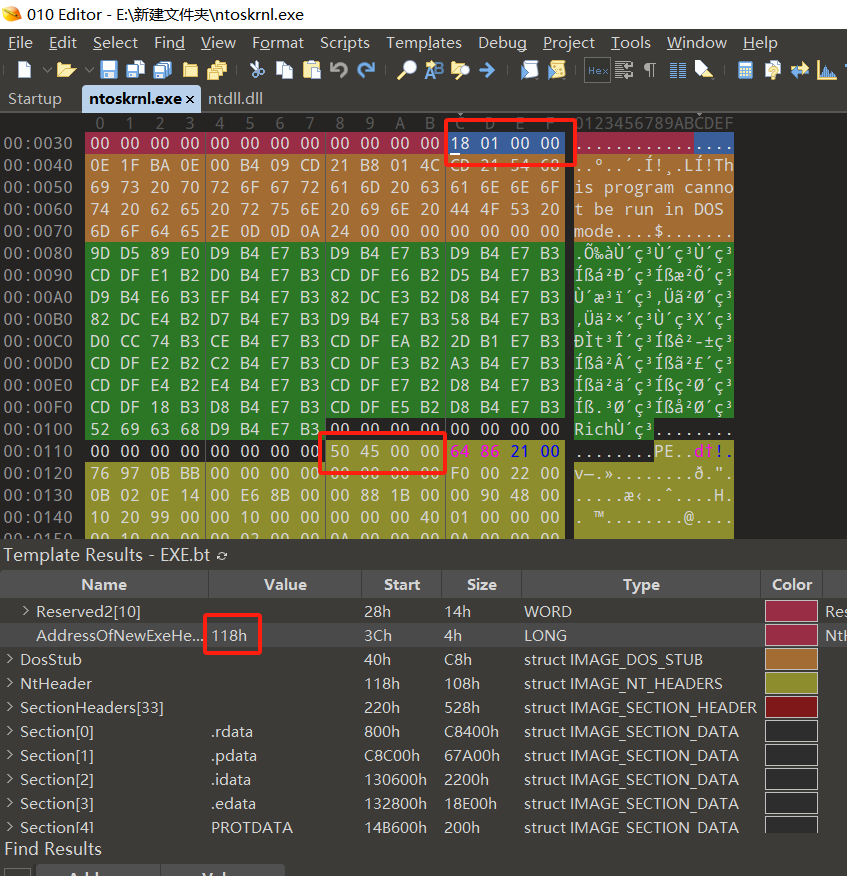
从上图可以看出,偏移值是0x118,文件头的起始位置也是0x118. 在这个部分的下面有一个DosStub,这部分没有什么含义,也没有什么用,官方文档有段对此的描述,我们大概看下就好。
The MS-DOS stub is a valid application that runs under MS-DOS. It is placed at the front of the EXE image. The linker places a default stub here, which prints out the message "This program cannot be run in DOS mode" when the image is run in MS-DOS. The user can specify a different stub by using the /STUB linker option. At location 0x3c, the stub has the file offset to the PE signature. This information enables Windows to properly execute the image file, even though it has an MS-DOS stub. This file offset is placed at location 0x3c during linking.
NtHeader
这个NtHeader,实际上就三个元素,签名,也就是上图中看到的PE字符串的样式(0x4550),然后是FileHeader和OptionalHeader
|
|
FileHeader
我们接下来介绍下这个文件头,结构体为
|
|
官方文档的定义在这里:https://learn.microsoft.com/zh-cn/windows/win32/api/winnt/ns-winnt-image_file_header
注意几个参数:
NumberOfSections,区段个数,表示有多少个区段
SizeOfOptionalHeader,OptionalHeader的大小,由此证明,OptionalHeader的大小是不确定的,需要在这里获得。
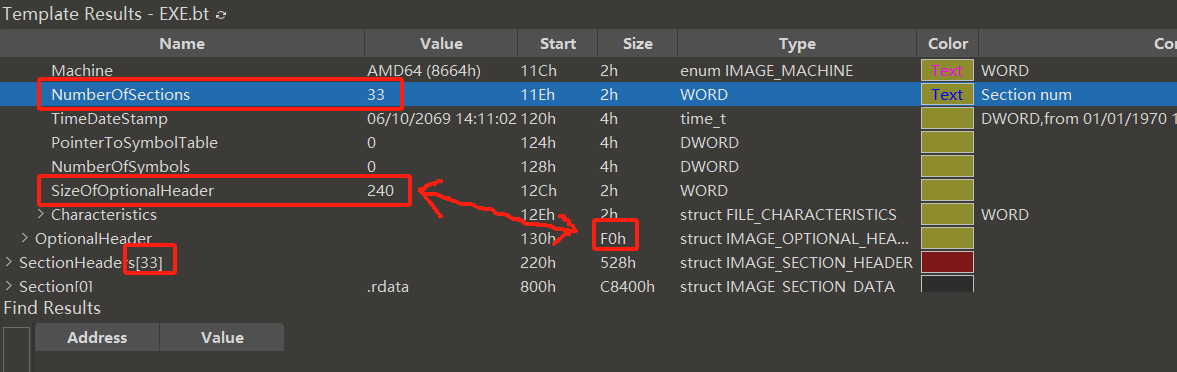
通过上图可以看到,区块数量和区块头的数量是一样 的,其次,OptionalHeader的大小和SizeOfOptionalHeader的值也是一样的。
OptionalHeader
OptionalHeader是在文件头的描述之外对其他信息的约定和描述,之所以Optional,也就是可选,主要是因为最后一个参数DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];会涉及到不同的表项,结构体的定义如下:
|
|
需要注意的几个参数:
AddressOfEntryPoint,pe文件的入口点函数的地址, 也就是可执行文件的起始地址,说白了就是我们的main函数的起始地址。
SectionAlignment,区段在内存中的对齐大小,一般是0x1000
FileAlignment,区段在文件中 对齐大小,一般是0x200(这部分在上面有过介绍)

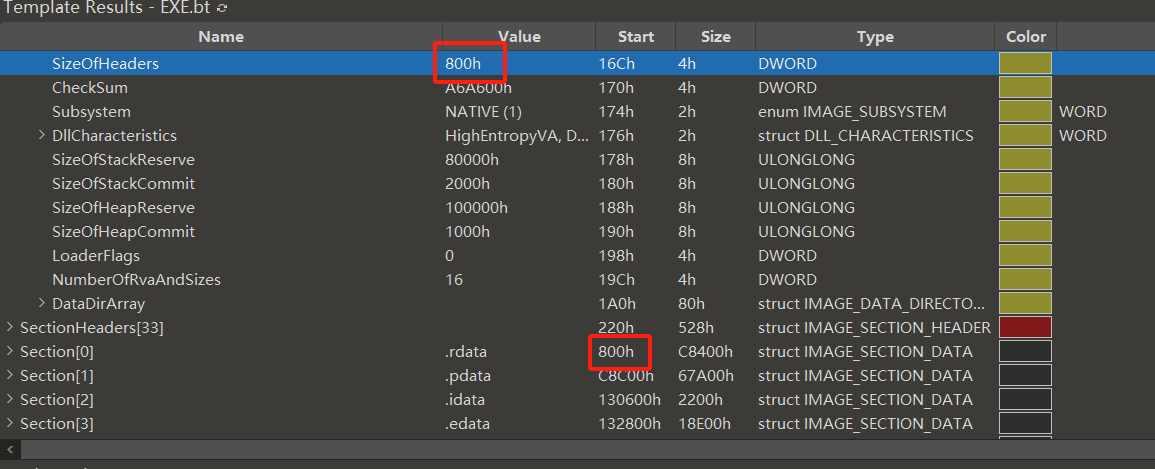
SizeOfHeaders,按照官方文档的描述这是一个组合大小,但是我一般就理解为直接从首地址到区段头的最后地址,总共的大小。
官方描述:以下项的组合大小,舍入为 FileAlignment 成员中指定的值的倍数。
IMAGE_DOS_HEADER 的e_lfanew成员 4 字节签名 IMAGE_FILE_HEADER 的大小 可选标头的大小 所有节标题的大小
DllCharacteristics,这个函数描述了一些dll的特征,但是其中有1位比较有意思,就是第7位,IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE,如果为1(64位的操作系统,也就是0x40位置),pe文件加载的时候,在内存中的文件的起始地址(逻辑地址)是随机的,如果为0,就是非随机的,以ImageBase这个参数的值为起始地址。(64位是0x14000000)
DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];这是一个结构体数组,每个成员都是IMAGE_DATA_DIRECTORY类型的结构体,结构体定义如下:
|
|
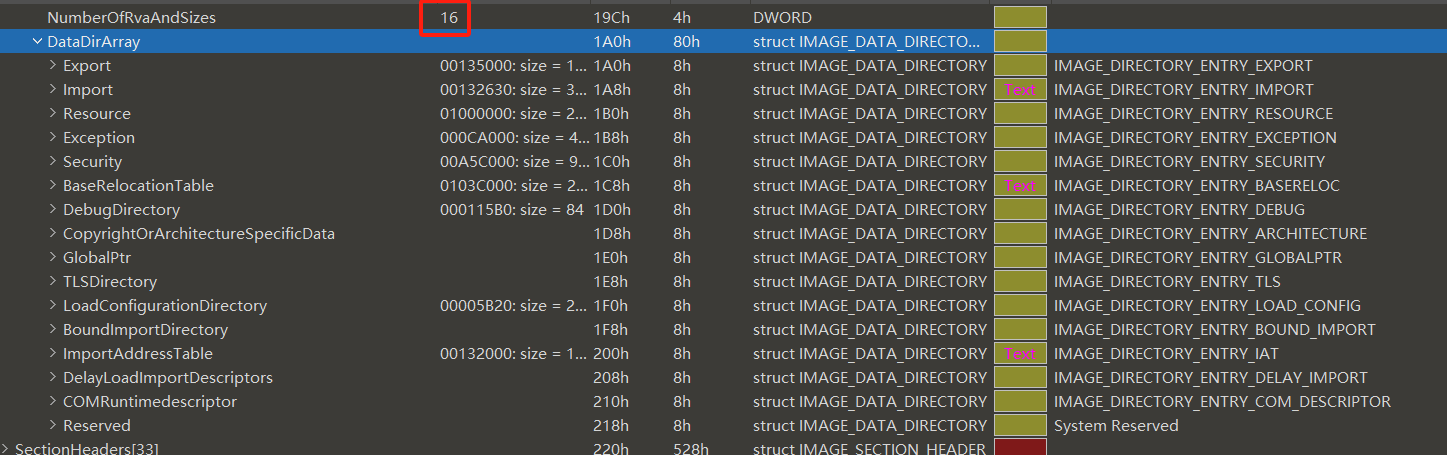
每一个结构体都描述的是一张表的地址和大小,而表的顺序按照官方文档一般是如下:
|
|
如图所示,可以看出内核文件的DataDirectory结构,但是并不是每一个pe文件都有这么多,毕竟这个可选的,所以,实际判断的时候需要通过NumberOfRvaAndSizes参数来确定,这个参数是DataDirectory数组的元素个数。
SectionHeaders
接下来就是描述每一个区段的区段头,每个区段头都是一样大小的结构体,定义如下:
|
|
注意几个参数:
Name[IMAGE_SIZEOF_SHORT_NAME],就是区段的名字,这个名字是一个字节数组,非常规字符串,总共8个字节空间,空的内容用null填充,但是正好8个字节,就没有末尾,所以不是异常常规的字符串。
Misc,一个联合体,更多用这个VirtualSize,作为内存展开之后的节的总大小,但不是对齐后的大小。
VirtualAddress,第一个区段在内存中相对于整个镜像首地址的偏移地址,如果是第一个区段一般是0x1000,因为整个头部分也没多大,不会超过0x1000
SizeOfRawData,文件原始大小,也就是硬盘大小。
PointerToRawData,区段在硬盘文件中的偏移位置(未加载到内存),如果是第一个区段,大小跟OptionalHeader里的SizeOfHeaders一样。
Characteristics,区段的一些属性,其中最后三位表示,可执行,可读取,可写入。 IMAGE_SCN_MEM_EXECUTE,0x20000000;IMAGE_SCN_MEM_READ,0x40000000;IMAGE_SCN_MEM_WRITE,0x80000000
三张常用表
在上面了解的DataDirectory有很多张表,其中有三个最常用的表,就是导出表、导入表和重定向表,接下来就让我们详细介绍下这三张表,不过在逐个介绍之前,要先了解一个前置知识,那就是文件和内存地址的计算方法。
RVA和FOA
在上文曾说过,一个pe文件,从硬盘加载到内存的过程中,会由操作系统创建一个虚拟的地址空间,我们成在这个空间的地址叫做VA,其次,文件加载的时候,因为随机地址的原因,文件的起始地址是不确定的,反正不是从0开始。再然后,又因为对齐的大小不同,加载到内存之后,头,以及各个区段,都会更加松散。因而会产生地址的变化
因此,我们把在硬盘上,文件中某个地址到文件起始地址(也就是0地址)的大小成为FOA,也就是文件相对地址,我们把在内存中,某个地址到镜像起始地址的大小成为RVA,也就是虚拟相对地址。
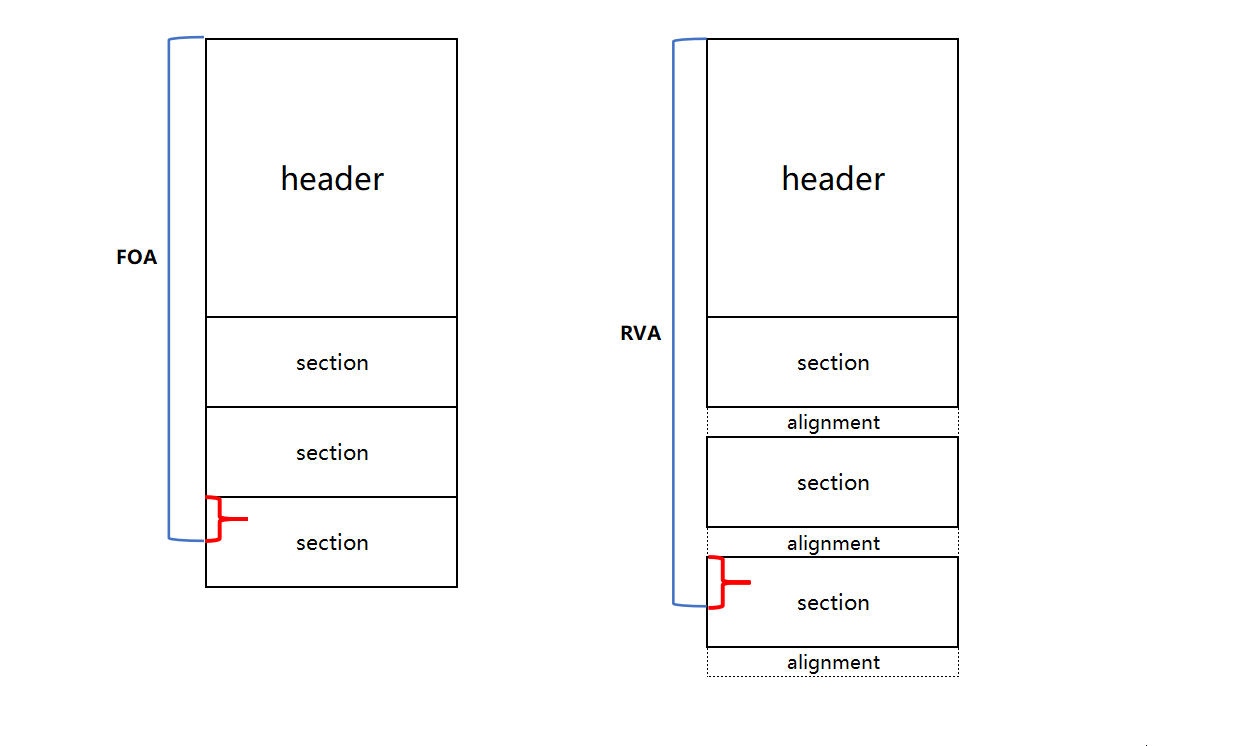
通过上图可以简单的看到两个概念的含义,也通过上面的描述知道,在加载内存的过程中,无论是RVA还是FOA,该位置距离其所在区段的位置是没有变化的,那么其实就可以很好的转换这个两个地址了,可以巧妙利用下面的公式。
FOA - 区段地址FOA == RVA - 区段RVA
导出表
首先,导出表的结构体定义如下,具体每个字段的含义可以在官方文档看,https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#the-edata-section-image-only,我们这里也来简单描述下。
|
|
其中最后三个参数单独介绍下:
AddressOfFunctions,这个是导出函数地址表,表里包含了每个导出函数的地址
AddressOfNames,这个是导出名称表,表里包含导出函数的名称(字符串)所对应的地址
AddressOfNameOrdinals,这个导出序号表,表的索引是名称表的索引,对应的值是地址表的索引,换句话说,在名称表中,索引位置n的函数,在函数地址表中的索引为序号表中索引n对应的值(一般我们称导出序号为索引+base)
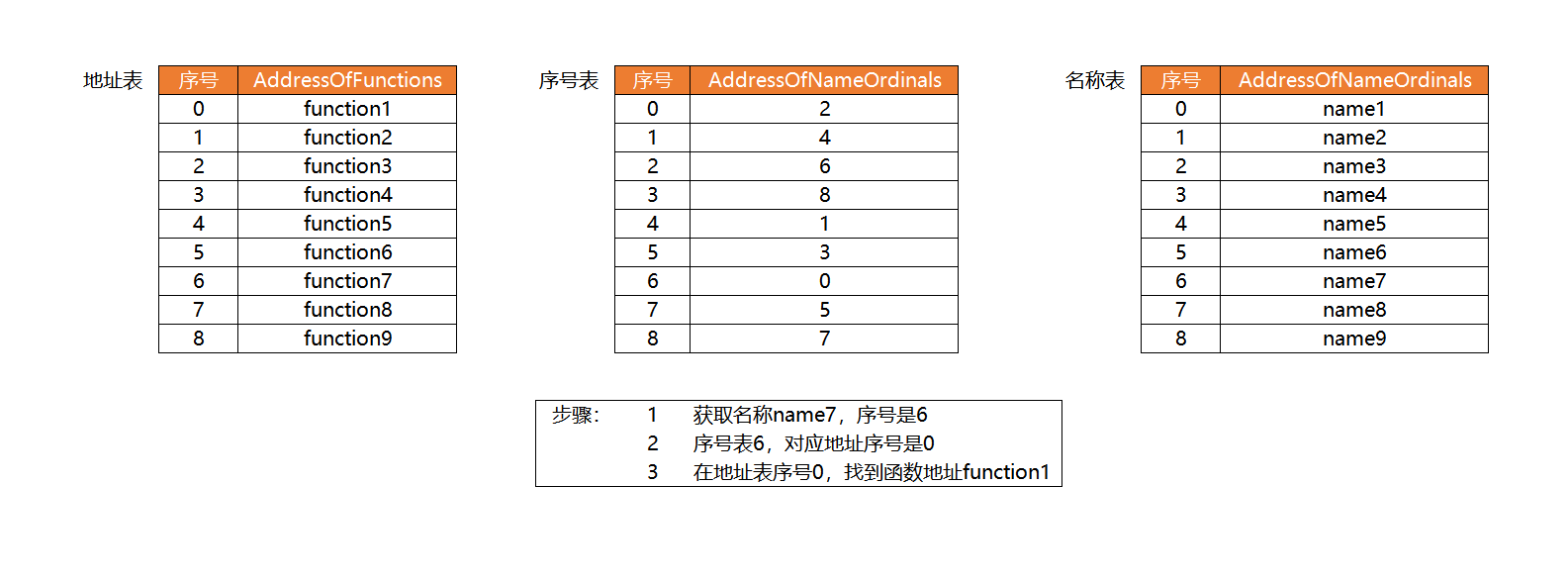
通过上面这个简图来看,如果已知函数名称想要知道函数地址:
1. 在名称表中搜索匹配到的对应名称,记录该索引n
2. 在序号表中获取索引n对应序号m
3. 在函数地址表中查找m索引的函数地址
因此想要知道函数名,就需要倒过来,在序号表里查,查找对应值等于目标函数在地址表里的索引,也就查到了序号表的索引,也就是名称表的索引,从而获取字符串地址。
举个例子
我们用010editor打开ntdll.dll,然后找到导出表的地址:这个值实际是RVA,但是右侧已经给我们注释了FOA,且是在.rdata区段。
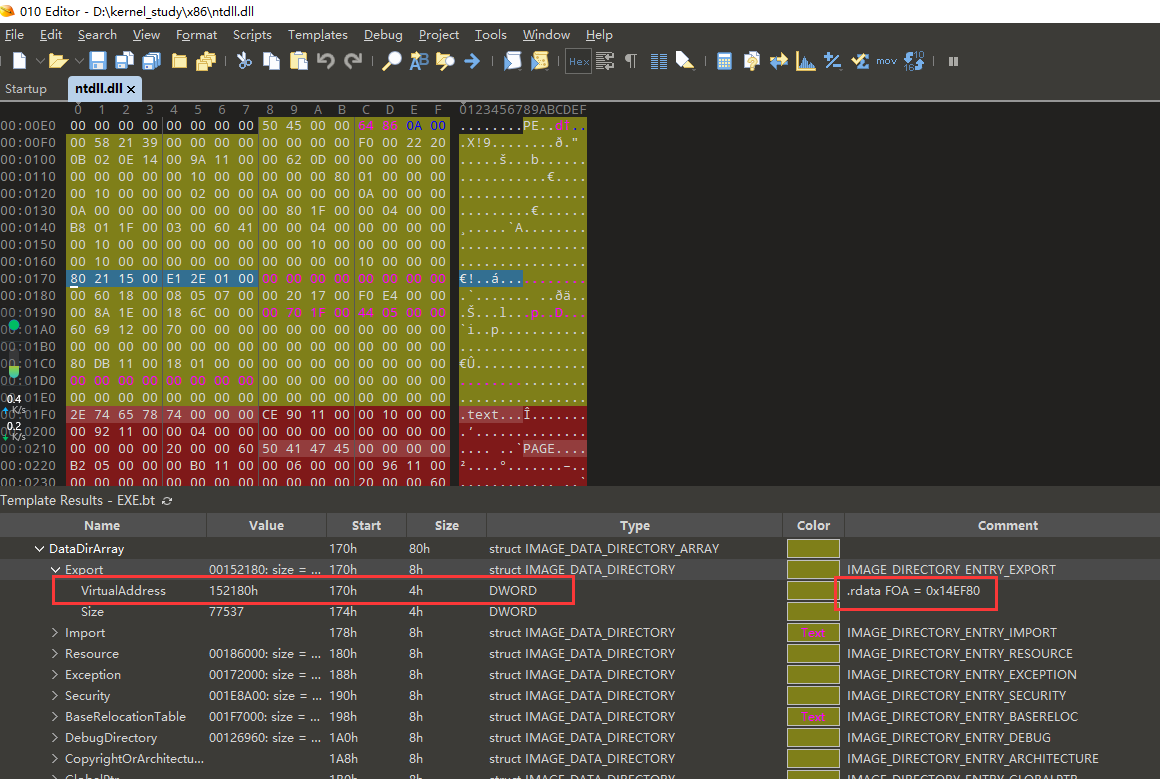
我们尝试跳转到改地址,Ctrl+G,输入地址0x14ef80,通过下图可以看到,三个RVA地址,这三个地址就是三个表,其次,注意到所在区段是.rdata,区段的RVA是0x11d000,区段的FOA是0x119e00,且base是8(也就是起始序号)
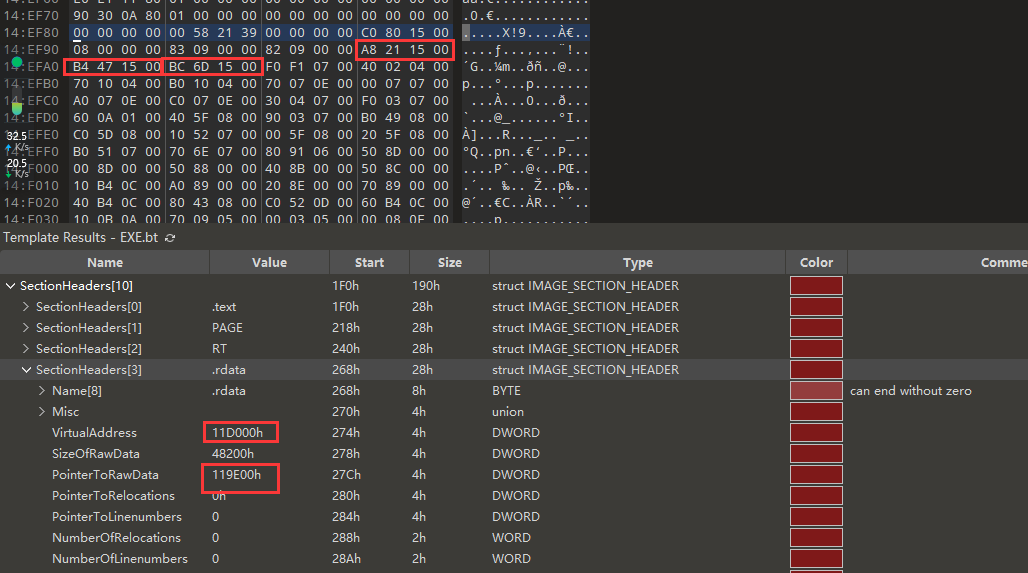
我们先进入名称表,也就是第二个地址:0x1547b4,这个地址是RVA,需要转化成FOA,那就用上面给的方法:0x1547b4 - 0x11d000 + 0x119e00 = 0x1515B4,跳转过去。
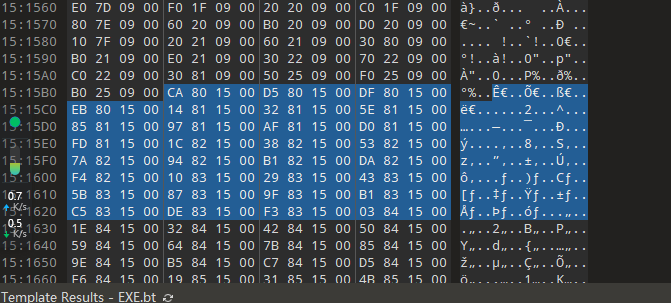
会发现如上图,很多相似地址,推断应该就是名称地址了,我们挑选一个,比如:索引为0x9位置的,也就是0x1581af,继续转换成FOA ,0x1581af - 0x11d000 + 0x119e00 = 0x154FAF,跳转过去可以看到,是一个叫做,AlpcGetMessageFromCompletionList的函数。
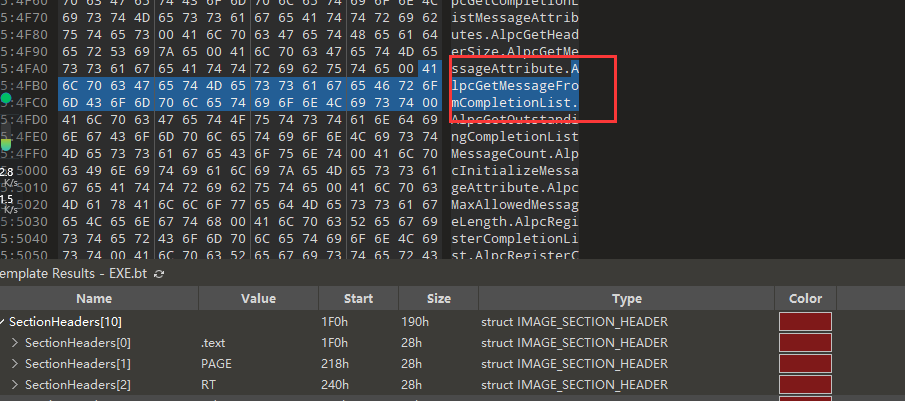
然后我们计算下符号表的位置:0x156dbc - 0x11d000 + 0x119e00 = 0x153BBC,跳转过去。
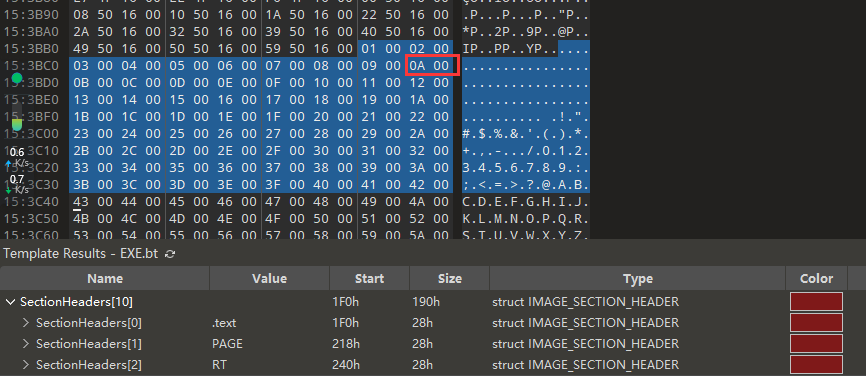
可以看到入上图的序号表,并且索引0x9位置对应的函数表索引是0xa,然后我们再计算函数地址表的FOA:0x1521A8 - 0x11d000 + 0x119e00 = 0x14EFA8,跳转过去。
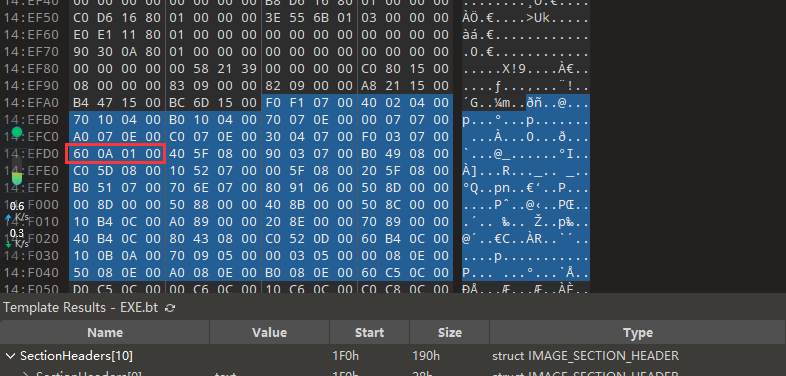
可以看到第0xa索引位置对应的RVA值是0x010a60,这就是函数的相对虚拟地址,且序号为0x8 + 0xa,那么到底对不对呢,我们用IDA验证一下。
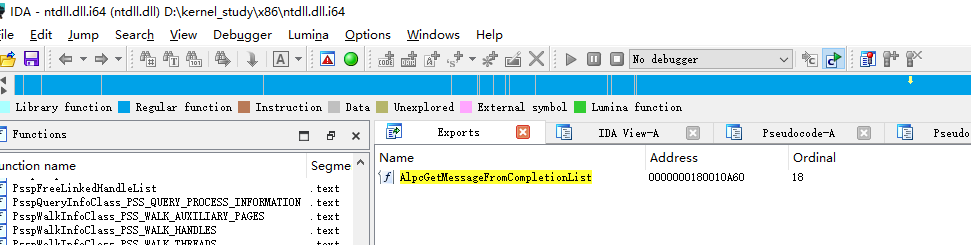
用IDA打开这个ntdll.dll,然后打开它的导出表标签页,Ctrl+F,查找这个函数,可以看到对应的VA地址是0x180010a60,查看OptionalHeader中的ImageBase可以看到其地址为0x180000000,所以这这个函数的RVA + ImageBase == VA,所以以上计算过程是对的,验证成功。

导入表
当一个执行文件在执行的时候,并不是所有函数,功能都是在自己文件里,甚至大多数你需要调用的函数都是在其他的dll文件里,所以,需要将这些文件导入到内存,一般是先把自己的文件设定好位置,然后接着去链接其他的dll文件,所以导入表就是这些要导入的函数的表。
|
|
以上各个字段的含义:
OriginalFirstThunk,对应的是导入函数名称表,简称INT的地址,对应的是_IMAGE_THUNK_DATA64这个结构体。
|
|
这个结构代表着可能是按照序号导入或者名称导入,如果最高位是1,就是按照序号导入,那么前两个字节就是序号,如果最高位位0,就是按照名称导入,那么前四个字节名称的地址,也是一个结构体_IMAGE_IMPORT_BY_NAME,定义如下:
|
|
这个结构的头两个字节是序号,也就是对应导入模块中导出表的函数对应序号(就是上面介绍的导出序号表里的序号),然后是函数名称的字符数组,最后以0结尾。
FirstThunk,如果未加载到内存,该指向依然是_IMAGE_THUNK_DATA64,如果加载了,则指向的_IMAGE_THUNK_DATA64结构体填充的就是函数的实际地址了。
再说一下这些表是如何排布的:
首先是_IMAGE_IMPORT_DESCRIPTOR,一个结构体代表一个导入文件,在这个地址后面连续有好多个,每个对应一个导入文件,直到在DataDirectory中描述导入表的大小结束。
其次,每一个_IMAGE_IMPORT_DESCRIPTOR也就是从OriginalFirstThunk或者FirstThunk开始,也是连续的_IMAGE_IMPORT_DESCRIPTOR结构体,直到值为0的该结构体。
举个例子
依然是找一个简单点的pe文件,用了32位的,原理一样就不麻烦再编译个64的exe了,找出对应的导入表位置,可以看到.rdata区段,且FOA为0x17ac。

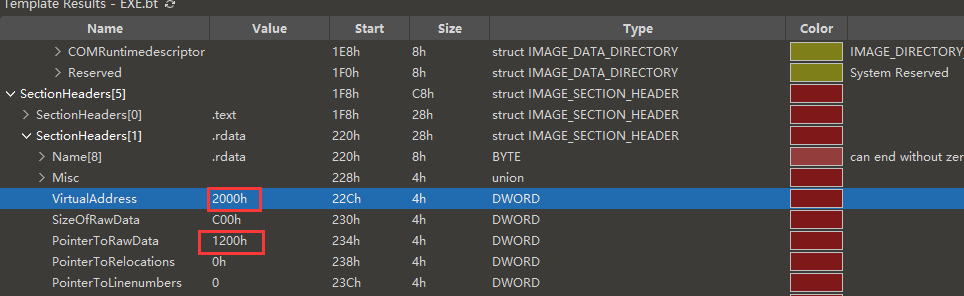
跳转过去之前先标记下其区段的RVA:0x2000,FOA:0x1200
跳转过去会发现下图,20个字节一组,也就是5个DWORD一组,就看第一组:0x2680,是_IMAGE_THUNK_DATA32的地址RVA,因为没加载到内存,0x2034也是_IMAGE_THUNK_DATA32的地址,0x2768是name的RVA。
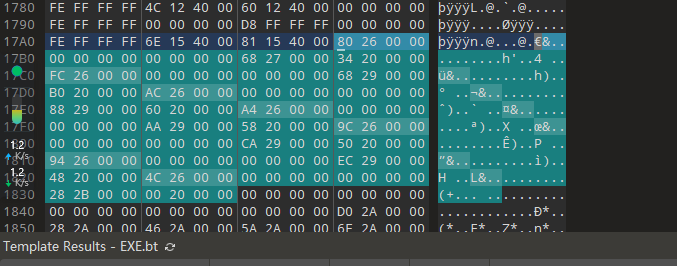
所以我们先计算name的FOA:0x2768 - 0x2000 + 0x1200 = 0x1968,跳转过去。
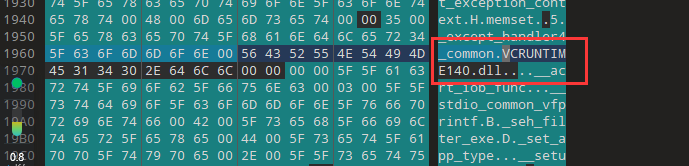
可以看到是VCRUNTIME140.dll这个dll,然后计算下OriginalFirstThunk的RVA,也就是第一个_IMAGE_THUNK_DATA64,0x2680 - 0x2000 + 0x1200 = 0x1880,跳转过去。
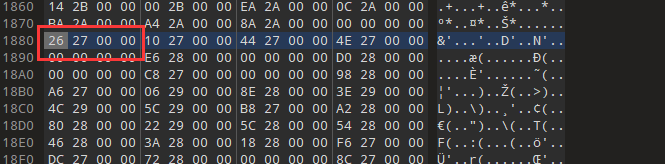
可以看到多个相似结构的DWORD,最高位为0,就是按照名字来导入的,这个DWORD就是RVA, 计算对应的IMAGE_IMPORT_BY_NAME的FOA:0x2726 - 0x2000 + 0x1200 = 0x1926
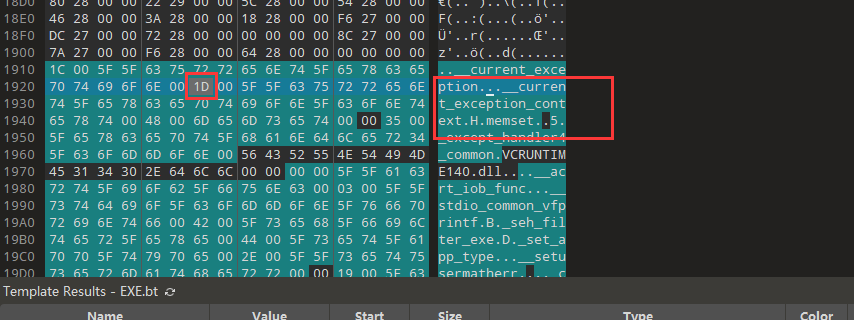
可以看到函数名的结构,其中1D是导出表那边对应的序号,我们依然可以用IDA验证下,发现就是这个函数确实是导入了,且实在VCRUNTIME140.dll中。

重定位表
在pe文件被加载到内存的过程中,不仅会加载镜像自身文件,还会加载相关联的所有dll文件。其次,在文件中约定了加载顺序以及imageBase为镜像基准地址,但是在加载的过程中,加载顺序以及基址是会改变的,这就导致了,在代码中有一些地址的硬编码(也就是写死了地址的编码),都是按照原基址的方式计算得到的,所以如果在加载过程中分配了新的基址,那这个硬编码就肯定是不对了。
在DataDirectory中,可以找到重定向表,并通过对应的地址跳转过去:

对应的是基址重定位块,重定位块是一块块相似的内容,每一个块都用来描述4K大小的数据(代码)页上有哪些硬编码需要重定向,这个块中有两部分内容。
第一部分:_IMAGE_BASE_RELOCATION这个结构体,结构体的定义如下:
|
|
第一个参数含义是所描述页的首地址(RVA),第二个参数是这个页中需要修改的硬编码个数
第二部分:跟在这个结构体后面就是标识每一个需要修改的硬编码的偏移地址,每一个偏移是2个字节表示,这个偏移地址是页内的偏移地址。但是一页只有4K,也就是2的12次方,所以,只需要12位就能确定硬编码在该页的位置。剩下的4位是用来表示重定位类型,具体可以参考这个文档。https://learn.microsoft.com/zh-cn/windows/win32/debug/pe-format#base-relocation-types
所以,高4位就是重定位类型,低12位就是硬编码在页内的偏移地址,一般重定位有三种常接触的类型:IMAGE_REL_BASED_ABSOLUTE,0x0,没有重定位,可忽略;IMAGE_REL_BASED_HIGHLOW,0x3,用在32位的程序里;IMAGE_REL_BASED_DIR64,0xA,用在64位的程序里。
然后,通过计算获取对应的偏移位置(RVA)= 页基址VirtualAddress + 0x0FFF & 偏移量,通过偏移位置找到对应的硬编码,如果是32位程序,编码就是一个DWORD,如果是64位程序,编码就是一个QWORD。
举个例子
我们找到一个加载dll比较多的exe,这样看起来更加方便,先用010editor打开并找到对应的重定位表的地址。
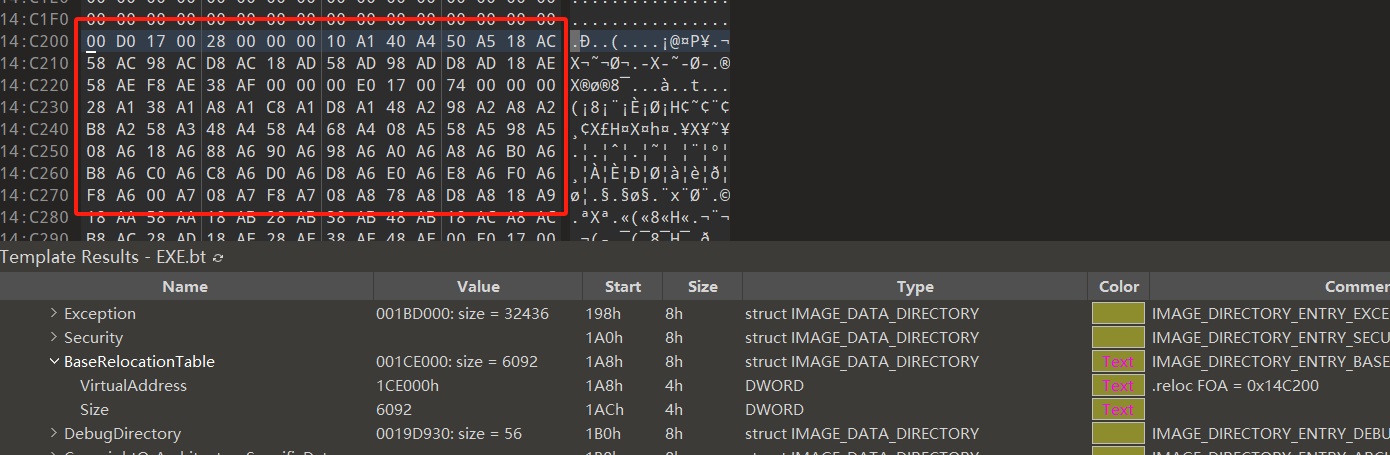
可以看到,这个块描述的是以0x17D000为基址的页,定位了0x28个硬编码地址。 先选择第一个偏移量进行计算,0xA110,其中A为64程序,页内偏移为0x110,页基址为0x17D000,那么该硬编码的RVA = 0x17D000 + 0x110 = 0x17D110
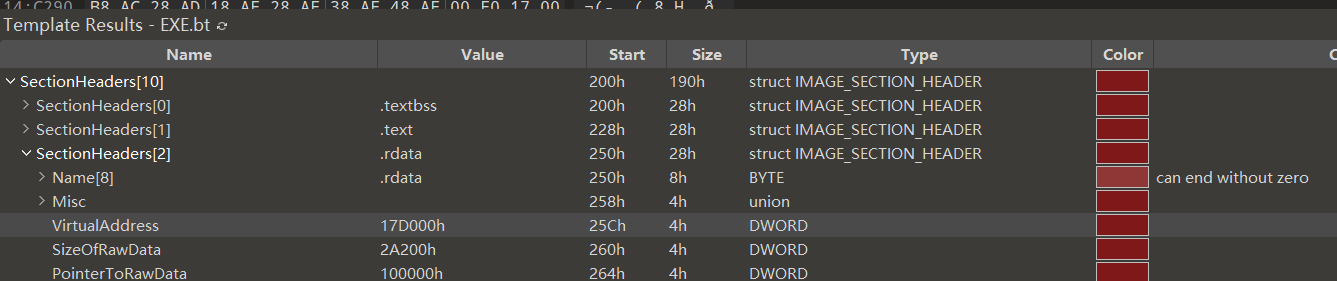
将该RVA转化成FOA,通过以上定位可以看到该地址在区段.rdata中,RVA为0x17D000,FOA为0x100000,那么转化后的FOA:0x17D110 - 0x17D000 + 0x100000 = 0x100110,跳转过去。
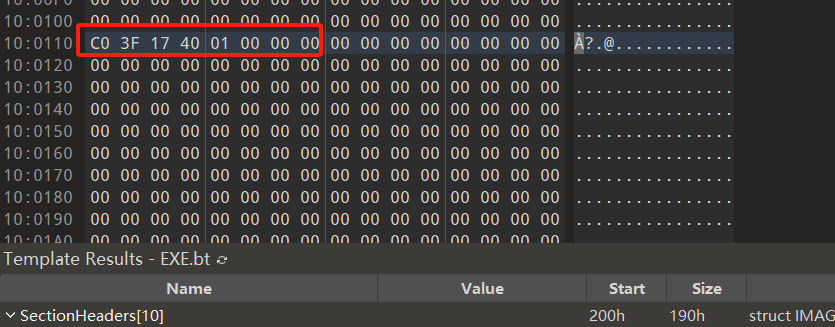
从上图可以看到对应一个QWORD的空间存放着一个地址硬编码:0x140173FC0,这是一个VA地址,我们尝试再x64dbg打开这个文件。
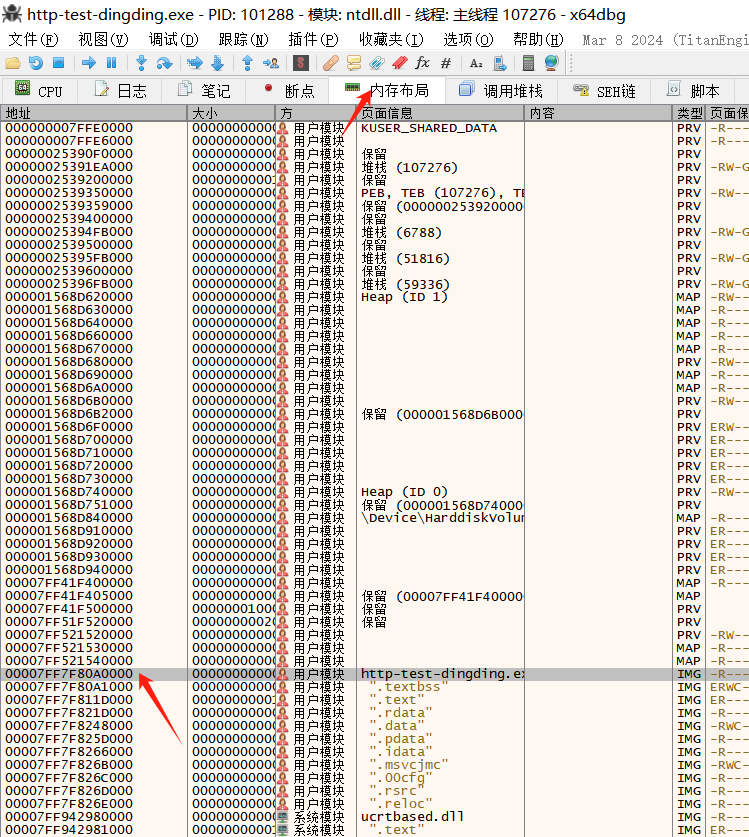
我们在内存布局中,找到镜像所在的区域,双击这个位置就能在CPU(反汇编区域)跳转到这里。然后右键任意地址,选择在反汇编中转到。
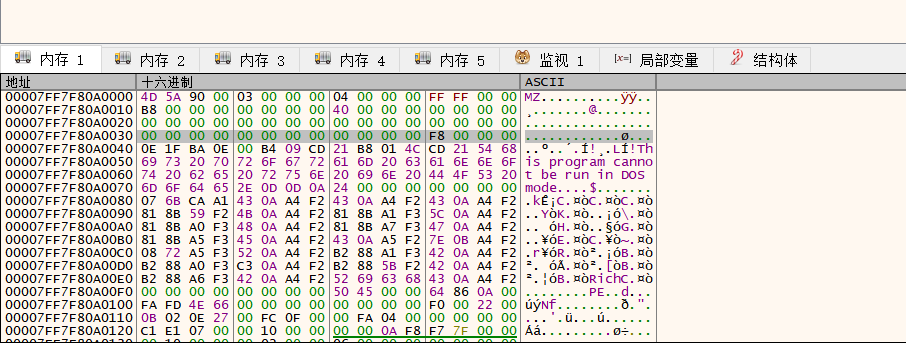
这样可以利用对应的偏移位置,也就是上面的RVA地址0x17D110,跳转过去。因为要看在内存中查看,所以先选择内存区域,然后,Ctrl + G,清空对话框内的内容,上面会有几个提示快捷键,选择RVA的方法。

然后把值换成0x17D110,并跳转过去。
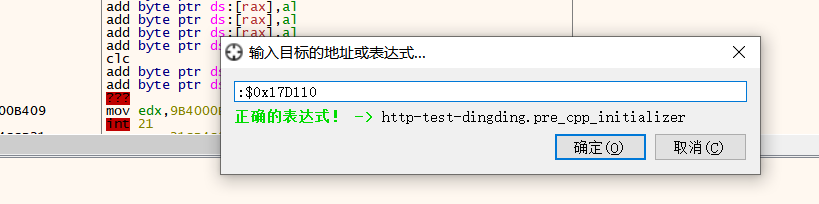
可以看到如下图所示,对应偏移位置的内容,已经变成了一个新的地址:0x7FF7F8213FC0
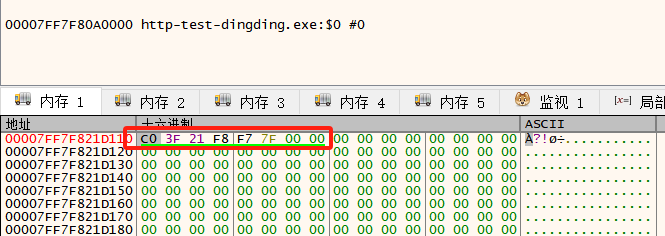
如下图可以看到,这个地址就是对应的一个函数的首地址,这个硬编码就是被重定向后的。
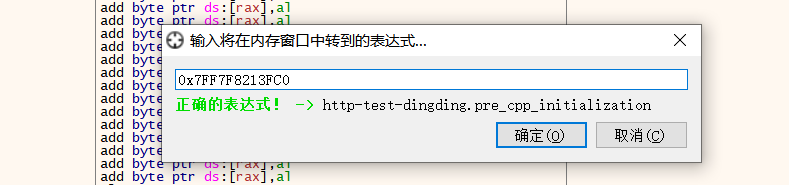
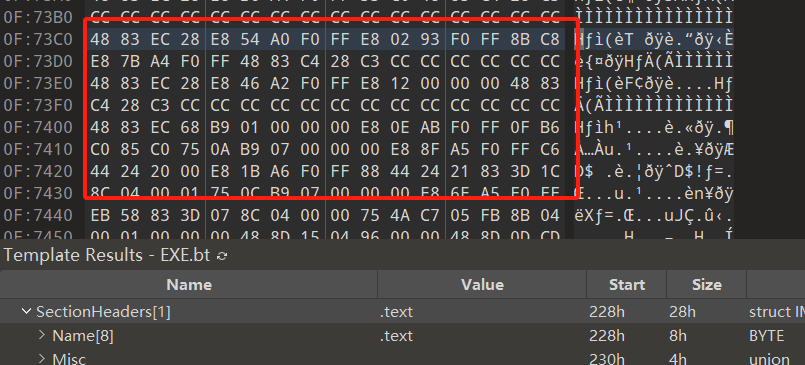
下图是跳转过去的位置的代码内容,这个是函数的编码,那么在文件中的是不是也是一样的呢,我们来计算下文件中的位置,文件里的硬编码地址是0x140173fc0,RVA就是0x173fc0(因为基址是0x140000000)
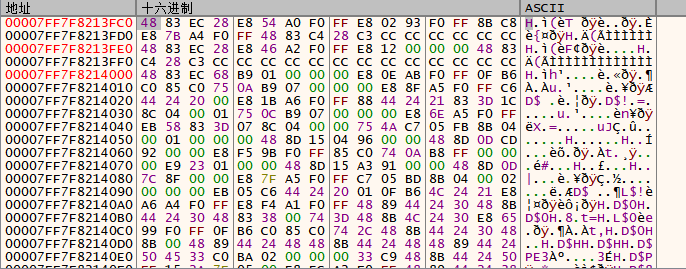
这个段是.text,区段的RVA是0x7D000,FOA是0x400,那么该硬编码指向的FOA:0x173fc0 - 0x7D000 + 0x400 = 0xF73C0,跳转过去。
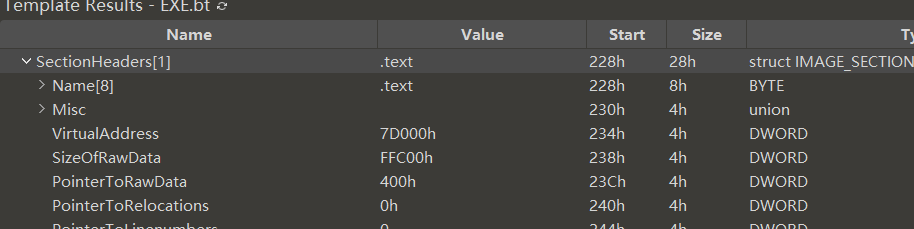
从下图可以看到这段代码的编码是一样的,那就是对应的代码函数位置。
到此,就把pe文件的一个基础情况介绍了一下,虽然除此之外还有很多涉及pe文件的内容,限于篇幅情况,后面有机会再进一步介绍。当然如果有精力的小伙伴可以去研究官方文档上更加详细的介绍。